Twitter’s New Data Fees Leave Scientists Scrambling for Funding – or Cutting Research
Twitter is ending free access to its application programming interface, or API. An API serves as a software “middleman” allowing two applications to talk to each other. An API is an accessible way to collect and share data within and across organizations. For example, researchers at universities unaffiliated with Twitter can collect tweets and other data from Twitter through their API.
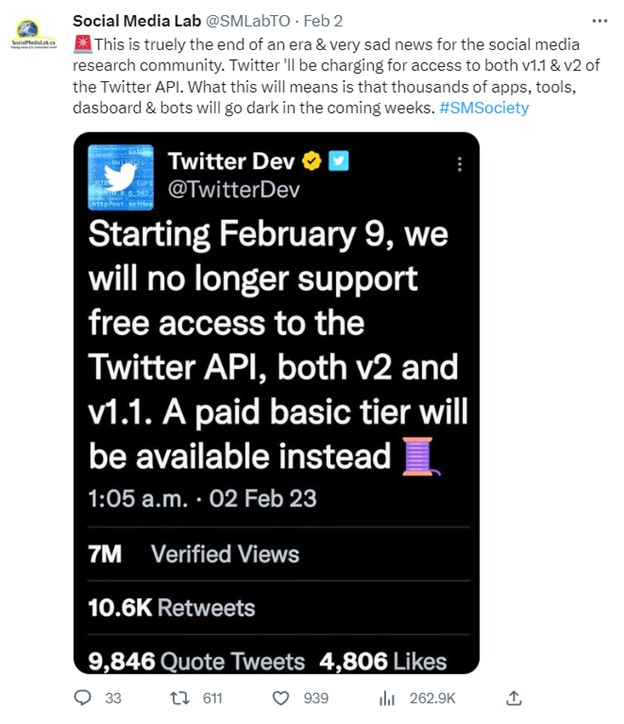
Starting Feb. 9, 2023, those wanting access to Twitter’s API will have to pay. The company is looking for ways to increase revenue to reverse its financial slide, and Elon Musk claimed that the API has been abused by scammers. This cost is likely to hinder the research community that relies on the Twitter API as a data source.
The Twitter API launched in 2006, allowing those outside of Twitter access to tweets and corresponding metadata, information about each tweet such as who sent it and when and how many people liked and retweeted it. Tweets and metadata can be used to understand topics of conversation and how those conversations are “liked” and shared on the platform and by whom.
This article was republished with permission from The Conversation, a news site dedicated to sharing ideas from academic experts. It represents the research-based findings and thoughts of, Jon-Patrick Allem, Assistant Professor of Research in Population and Public Health Sciences, University of Southern California.
As a scientist and director of a research lab focused on collecting and analyzing posts from social media platforms, I have relied on the Twitter API to collect tweets pertinent to public health for over a decade. My team has collected more than 80 million observations over the past decade, publishing dozens of papers on topics from adolescents’ use of e-cigarettes to misinformation about COVID-19.
Twitter has announced that it will allow bots that it deems provide beneficial content to continue unpaid access to the API, and that the company will offer a “paid basic tier,” but it’s unclear whether those will be helpful to researchers.
Blocking Out and Narrowing Down
Twitter is a social media platform that hosts interesting conversations across a variety of topics. As a result of free access to the Twitter API, researchers have followed these conversations to try to better understand public attitudes and behaviors. I’ve treated Twitter as a massive focus group where observations – tweets – can be collected in near real time at relatively low cost.
The Twitter API has allowed me and other researchers to study topics of importance to society. Fees are likely to narrow the field of researchers who can conduct this work, and narrow the scope of some projects that can continue. The Coalition for Independent Technology Research issued a statement calling on Twitter to maintain free access to its API for researchers. Charging for access to the API “will disrupt critical projects from thousands of journalists, academics and civil society actors worldwide who study some of the most important issues impacting our societies today,” the coalition wrote.
The financial burden will not affect all academics equally. Some scientists are positioned to cover research costs as they arise in the course of a study, even unexpected or unanticipated costs. In particular, scientists at large research-heavy institutions with grant budgets in the millions of dollars are likely to be able to cover this kind of charge.
However, many researchers will be unable to cover the as yet unspecified costs of the paid service because they work on fixed or limited budgets. For example, doctoral students who rely on the Twitter API for data for their dissertations may not have additional funding to cover this charge. Charging for access to the Twitter API will ultimately reduce the number of participants working to understand the world around us.
The terms of Twitter’s paid service will require me and other researchers to narrow the scope of our work, as pricing limits will make it too expensive to continue to collect as much data as we would like. As the amount of data requested goes up, the cost goes up.
We will be forced to forgo data collection on some topic areas. For example, we collect a lot of tobacco-related conversations, and people talk about tobacco by referencing the behavior – smoking or vaping – and also by referencing a product, like JUUL or Puff Bar. I add as many terms as I can think of to cast a wide net. If I’m going to be charged per word, it will force me to rethink how wide a net I cast. This will ultimately reduce our understanding of issues important to society.
Difficult Adjustments
Costs aside, many academic institutions are likely to have a difficult time adapting to these changes. For example, most universities are slow-moving bureaucracies with a lot of red tape. To enter into a financial relationship or complete a small purchase may take weeks or months. In the face of the impending Twitter API change, this will likely delay data collection and potential knowledge.
Unfortunately, everyone relying on the Twitter API for data was given little more than a week’s notice of the impending change. This short period has researchers scrambling as we try to prepare our data infrastructures for the changes ahead and make decisions about which topics to continue studying and which topics to abandon.
If the research community fails to properly prepare, scientists are likely to face gaps in data collection that will reduce the quality of our research. And in the end that means a loss of knowledge for the world.